Security
Security for AI agents in Webex Contact Center is not just about blocking unsafe prompts. It is about protecting the full interaction lifecycle: inputs, prompts, knowledge, actions, outputs, logs, and operational controls.
A secure AI agent should not only respond safely. It should also be designed, tested, monitored, and governed in a way that reduces risk before, during, and after deployment.
Why Security Matters
AI agents introduce a broader attack surface than traditional scripted bots or fixed workflows. In a contact center environment, that risk can include:
- prompt injection
- jailbreak attempts
- harmful or toxic outputs
- data leakage
- unsafe tool usage
- weak tenant isolation
- poor observability
- compliance failures
- multi-turn manipulation across a conversation
This means AI agent security must be treated as an end-to-end discipline rather than a single moderation step.
Current Security Foundations
The current Webex AI Agent security posture is built around several core layers.
Responsible AI Governance
AI-powered features are reviewed through Cisco's Responsible AI framework and AI Impact Assessment process. This is intended to ensure that trust, safety, and risk evaluation are part of the product lifecycle.
Tenant Isolation and Ephemeral LLM Calls
The current architecture emphasizes tenant isolation and short-lived LLM interactions.
Key design ideas include:
- customer data is isolated in Cisco cloud environments
- LLM requests are scoped using tenant identifiers
- LLM calls are ephemeral rather than long-lived sessions
- conversation artifacts are retained on the Cisco side, not persisted at the LLM provider layer
This reduces the chance of cross-tenant bleedover and limits data persistence outside Cisco-managed systems.

Runtime Guardrails Available Today
Current runtime protections include standard guardrails that screen inputs and outputs for common classes of unsafe behavior.
Examples shown in the current security material include:
Toxicity - DefaultToxicity - ExpandedHarmJailbreak
These are intended to catch clearly unsafe content and attempts to manipulate or override the model.

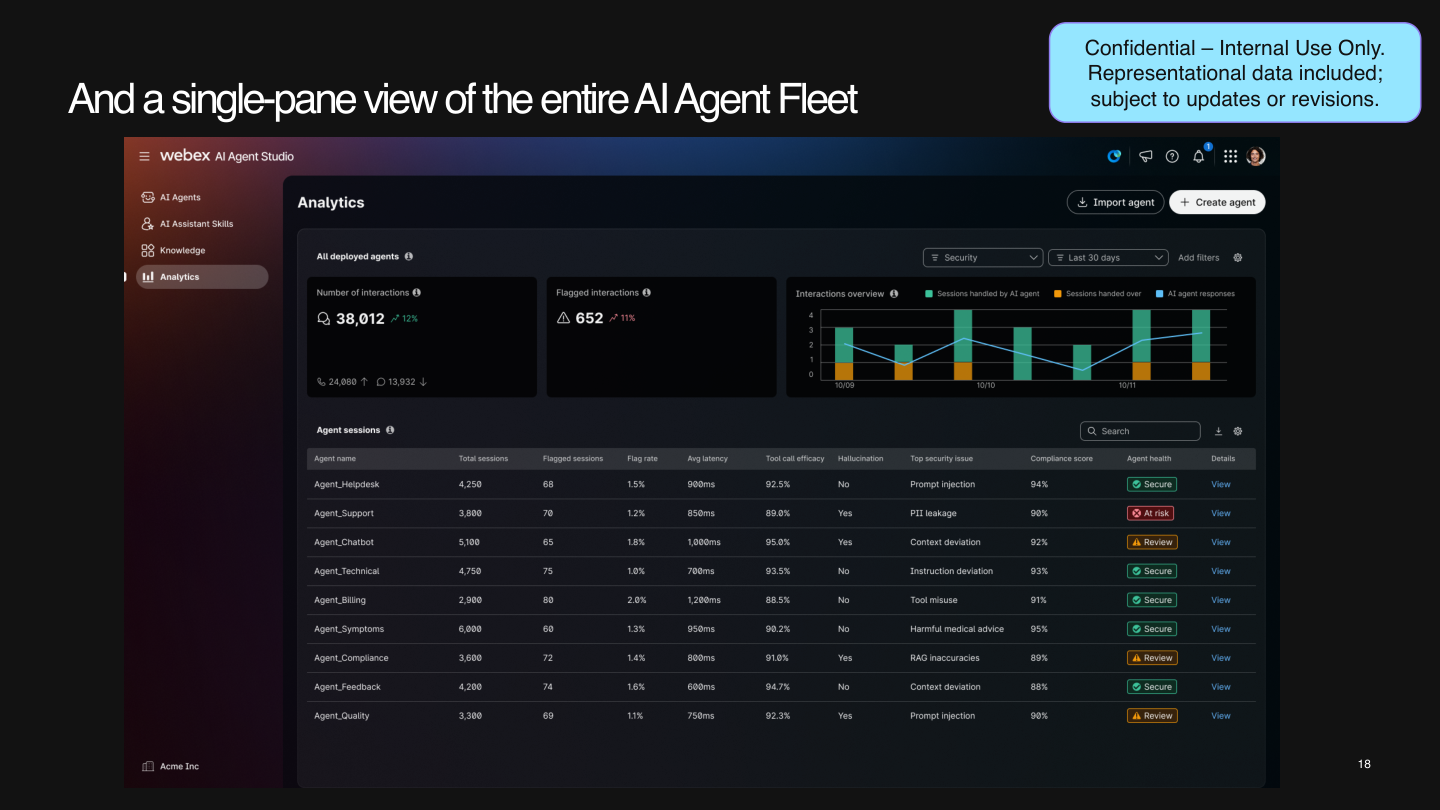
Runtime Visibility and Analytics
A major part of security is visibility. The current product direction includes richer analytics so admins can review:
- flagged interactions
- agent health
- top security issues
- compliance-related indicators
- session-level details
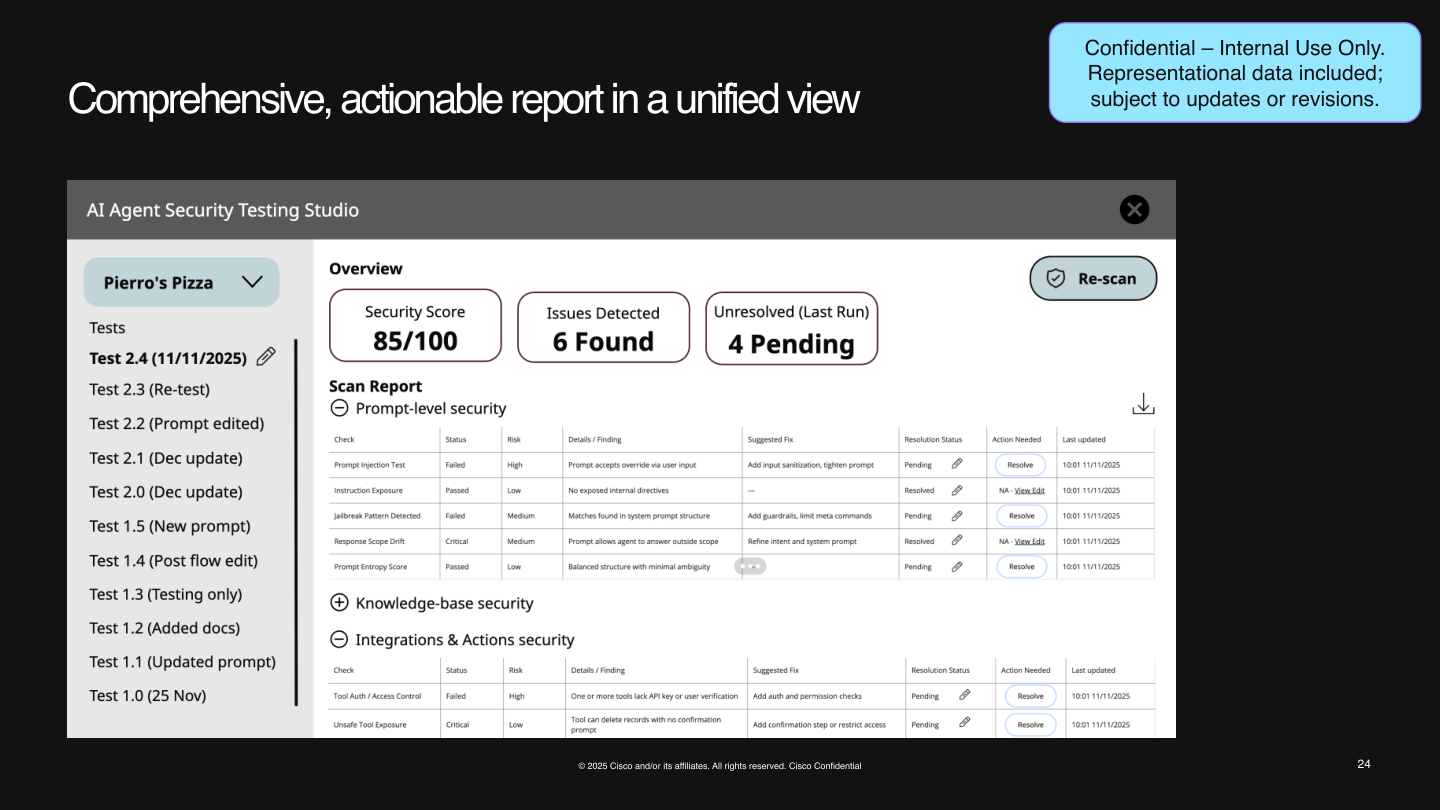
Design-Time Security Testing
One of the strongest security directions is shifting validation earlier in the lifecycle.
Instead of discovering problems only after launch, design-time testing is intended to help catch issues such as:
- prompt injection
- prompt manipulation
- harmful content generation
- privacy and data security issues
- integration and action risks
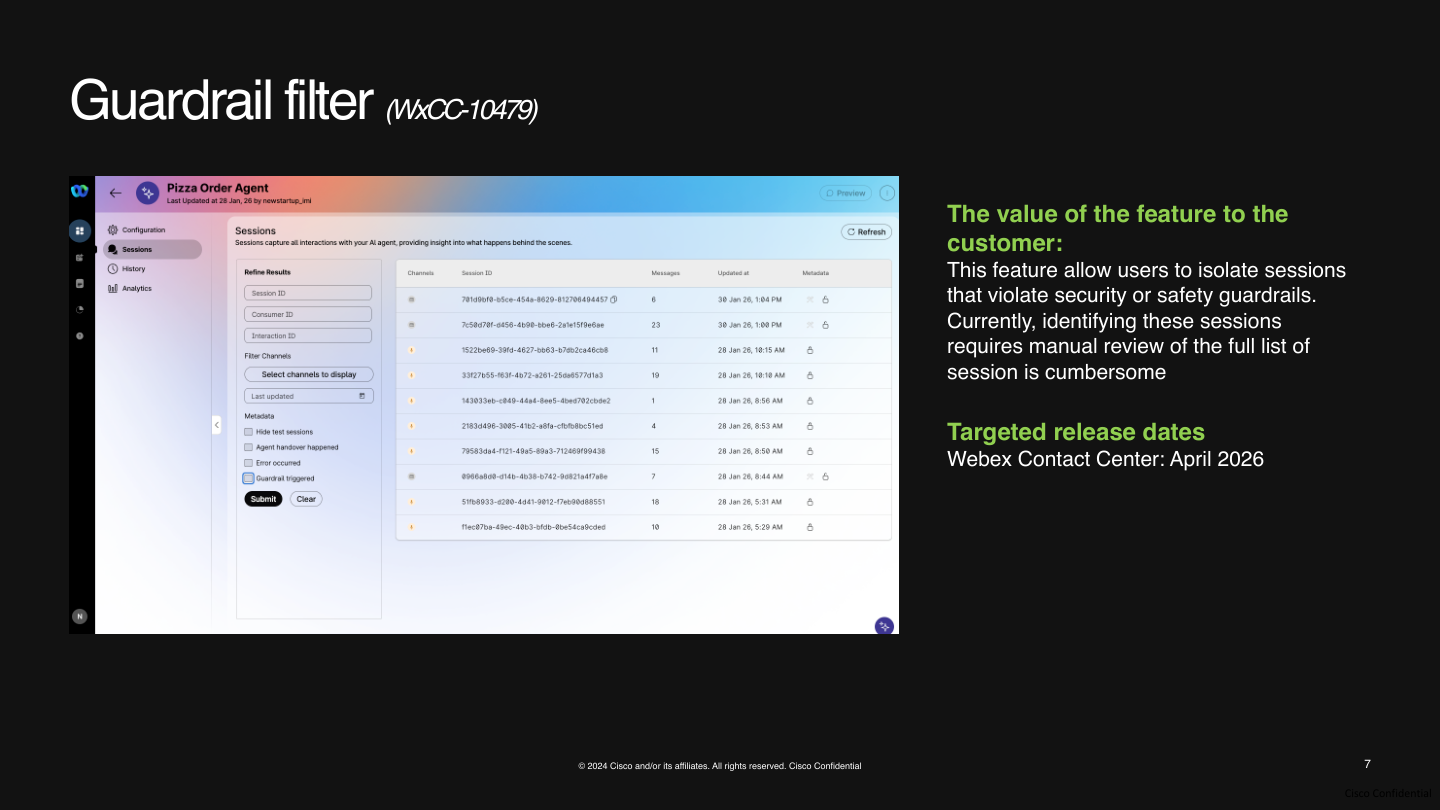
Security Guardrail Filter
A planned filter will help teams isolate sessions where a security or safety rail was triggered instead of manually reviewing the full session list.
AI Defense Integration
The long-term direction is not to rely only on baseline built-in guardrails. The product strategy points toward pairing standard protections with Cisco AI Defense as an optional advanced layer.
Current framing suggests:
- Webex AI or Collab AI remains the default
- AI Defense is offered as an advanced security option
- packaging and pricing are still evolving
- deeper platform integration is part of the longer-term plan
Security Best Practices
Even with strong platform controls, customers still own important parts of the final security posture.
1. Minimize Exposure
Only expose the data, tools, and actions the agent truly needs.
- reduce unnecessary context
- avoid broad tool permissions
- keep knowledge sources scoped and curated
2. Separate Conversation From Control
Prompts should define behavior, but critical workflow control should not rely on natural-language instructions alone.
Use structured logic, validated tools, or workflow controls when reliability matters.
3. Validate Exact Values Outside the Model
For exact matches such as site names, policy values, IDs, or approved actions, use a trusted system of record or tool call instead of asking the model to infer from text.
4. Assume Adversarial Inputs Will Happen
Design for:
- jailbreak attempts
- role confusion
- indirect prompt injection through retrieved content
- harmful or manipulative user behavior
- gradual multi-turn steering
5. Test Before Deploying
Do not wait for live traffic to reveal weaknesses.
Before deployment, test for:
- prompt injection
- unsafe tool invocation
- policy violations
- hallucinated outputs
- escalation failures
- disclosure or compliance gaps
6. Monitor After Deploying
Security is not complete at launch.
Review:
- flagged sessions
- recurring attack patterns
- false positives
- model drift or output quality issues
- escalation and containment behavior
7. Keep Human Escalation Available
A secure system should know when not to continue autonomously.
Use escalation when:
- the request is ambiguous
- the user is frustrated
- policy restrictions apply
- the model is uncertain
- the action is high risk
Recommended Operating Model
A practical way to think about Webex Contact Center AI agent security is:
- use built-in platform guardrails as a baseline
- keep prompts, tools, and knowledge narrow
- test aggressively before deployment
- monitor continuously after deployment
- plan for stronger controls as roadmap features mature
Practical Takeaway
The most important lesson is this:
A secure AI agent is not created by one guardrail, one prompt, or one moderation check. It is created by combining safe architecture, constrained actions, design-time testing, runtime monitoring, and clear governance.
For Webex Contact Center AI agents, the current platform provides a strong starting point. The next wave of product improvements is focused on making that security posture more observable, more tunable, and better suited for real production risk
Security FAQ
This FAQ summarizes common security, privacy, governance, and compliance questions that teams may ask when evaluating Webex Contact Center AI agents.
1. How are the models tested and validated?
Webex AI Agent is validated through Cisco’s Responsible AI governance process, including an AI Impact Assessment for AI-powered capabilities, along with ongoing human-led testing, review, and quality assurance.
For autonomous AI agents, models such as GPT-4o and GPT-4.1-mini have been selected based on Cisco research and benchmarking across factors such as:
- conversational quality
- latency
- cost efficiency
Cisco continues to evaluate third-party models over time to maintain and improve performance. However, the platform does not currently provide a fixed tested-version matrix or explicit pass/fail threshold documentation for the full end-to-end solution.
2. What third-party providers are involved?
Autonomous AI agents use Microsoft Azure OpenAI Service for large language model capabilities.
Depending on the AI engine selected, additional providers may be used for speech-related services. For example:
- ElevenLabs for text-to-speech
- Deepgram for speech-to-text
Cisco applies vendor review, security assessment, and safety evaluation processes when working with these providers. Cisco also states that customer data sent to these providers is not permitted to be used for model training or improvement, and is not retained beyond the immediate transaction.
For U.S.-based deployments, supported speech services are processed in U.S. regions.
3. How is model behavior monitored?
Cisco uses telemetry to monitor service performance, availability, and operational health of the underlying AI infrastructure. In some cases, requests can be rerouted when technical issues such as latency or regional degradation occur.
However, Webex AI Agent Studio is a platform that allows customers to define their own:
- goals
- prompts
- instructions
- knowledge sources
- actions
Because of that, customers remain responsible for validating and monitoring the behavior of the agents they configure.
Today, the platform provides visibility through session review and analytics capabilities, but it does not currently offer a formal Cisco-managed cadence for proactively reporting issues such as:
- hallucinations
- model drift
- safety degradation
Additional observability and analytics capabilities are planned on the roadmap.
4. How are fairness and bias handled?
Fairness and bias are considered within Cisco’s broader AI safety and governance framework.
For autonomous agents, the underlying third-party models may still reflect societal bias. For that reason, fairness-related review should include the transparency and responsible AI materials provided by the model provider.
For more deterministic or scripted agents, the risk of biased language generation is generally reduced because those experiences rely more heavily on customer-defined intents, rules, and training data.
Cisco’s governance framework applies to the platform, but there is not currently a published recurring bias-reporting cadence or statistical bias report specific to each autonomous or scripted deployment.
5. Where does processing happen and what about data locality?
Webex AI Agent can be deployed in supported regions, including U.S. deployments such as produs1.
For the use case covered in this material:
- speech-to-text and text-to-speech are U.S.-only
- telemetry and logs are stored in the U.S.
At the same time, Cisco operates as a global cloud service organization, so authorized support and engineering personnel outside the U.S. may access logs for support and operational purposes where needed.
Teams with strict residency requirements should confirm locality and support-access expectations during final security and privacy review.
6. How transparent are the inputs, outputs, and system behavior?
Customers can control important parts of the agent experience, including:
- business logic
- agent instructions
- allowed actions
- grounding content
- escalation design
However, customers do not currently have full visibility into system-level prompts or the ability to override guardrails directly.
The platform roadmap indicates that additional features are planned to help customers:
- manage safety and compliance policies
- control guardrails more directly
- define enterprise-level policies
- enforce agent-level security posture more consistently
7. What are the retention and deletion policies?
Retention depends on the service component.
For AI Agent Studio specifically:
- the default retention period is 90 days
For Contact Center-related content, retention may depend on the applicable customer setup, contractual policy, and service configuration.
In some cases, retention can be configured at the organization level. In other cases, changes may require Cisco support rather than self-service administration.
When deletion is requested, Cisco states that it endeavors to delete requested data from its systems within 30 days unless retention is required for legitimate business purposes.
For third-party model providers, Cisco states that customer data processed through those services is not used for model training or improvement and is not retained beyond the immediate transaction. If a deployment requires explicit zero-retention confirmation for every provider involved, that should be validated as part of the final security and privacy review.